MapReduce is the method of creating an inventory of items and working an operation over each and every object within the listing (i.e., map) to both produce a brand new listing or calculate a unmarried price (i.e., scale back).
MapReduce Analogy
Allow us to start this MapReduce educational and check out to know the idea that of MapReduce, perfect defined with a situation: Imagine a library that has an intensive selection of books that survive a number of flooring; you need to rely the entire collection of books on each and every flooring.
Get In-Call for Talents to Release Your Information Profession
Put up Graduate Program In Information EngineeringDiscover Route
What could be your way?
Finishing this process on your own could be tedious. A distinct way could be to assign each and every flooring to a colleague in order that the books from each and every flooring are counted concurrently through other folks. This way is named parallel processing, making duties more uncomplicated to finish.
Technically, parallel processing refers to the use of more than one machines that give a contribution their RAM and CPU cores for information processing. That is the idea that of the Hadoop framework, the place you no longer simplest retailer information throughout other machines, however you’ll be able to additionally procedure the knowledge in the community.
The Apache Hadoop and Spark parallel computing techniques let programmers use MapReduce to run fashions over huge disbursed units of knowledge, in addition to use complex statistical and gadget finding out ways to make predictions, to find patterns, discover correlations, and so on.
Allow us to perceive what MapReduce precisely is within the subsequent phase of this MapReduce educational.
MapReduce Evaluation
MapReduce is the processing engine of Hadoop that processes and computes huge volumes of knowledge. It is likely one of the maximum not unusual engines utilized by Information Engineers to procedure Large Information. It permits companies and different organizations to run calculations to:
- Resolve the cost for his or her merchandise that yields the best possible earnings
- Know exactly how efficient their promoting is and the place they must spend their advert bucks
- Make climate predictions
- Mine internet clicks, gross sales data bought from outlets, and Twitter trending subjects to resolve what new merchandise the corporate must produce within the upcoming season
Earlier than MapReduce, those calculations had been sophisticated. Now, programmers can take on issues like those with relative ease. Information scientists have coded complicated algorithms into frameworks in order that programmers can use them.
Corporations now not want a complete division of Ph.D. scientists to style information, nor do they want a supercomputer to procedure huge units of knowledge, as MapReduce runs throughout a community of cheap commodity machines.
There are two stages within the MapReduce programming style:
- Mapping
- Lowering
The next a part of this MapReduce educational discusses each those stages.
Mapping and Lowering
A mapper magnificence handles the mapping segment; it maps the knowledge provide in several datanodes. A reducer magnificence handles the decreasing segment; it aggregates and decreases the output of various datanodes to generate the general output.
Information this is saved on more than one machines go thru mapping. The general output is got after the knowledge is shuffled, looked after, and diminished.
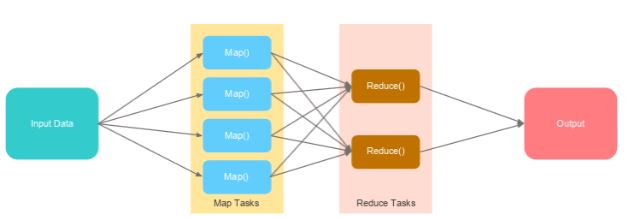
Enter Information
Hadoop accepts information in more than a few codecs and retail outlets it in HDFS. This enter information is labored upon through more than one map duties.
Map Duties
Map reads the knowledge, processes it, and generates key-value pairs. The collection of map duties will depend on the enter record and its layout.
Generally, a record in a Hadoop cluster is damaged down into blocks, each and every with a default dimension of 128 MB. Relying upon the dimensions, the enter record is divided into more than one chunks. A map process then runs for each and every bite. The mapper magnificence has mapper purposes that come to a decision what operation is to be carried out on each and every bite.
Scale back Duties
Within the decreasing segment, a reducer magnificence plays operations at the information generated from the map duties thru a reducer serve as. It shuffles, varieties, and aggregates the intermediate key-value pairs (tuples) into a collection of smaller tuples.
Output
The smaller set of tuples is the general output and will get saved in HDFS.
Allow us to have a look at the MapReduce workflow within the subsequent phase of this MapReduce educational.
MapReduce Workflow
The MapReduce workflow is as proven:
- The enter information that must be processed the use of MapReduce is saved in HDFS. The processing will also be achieved on a unmarried record or a listing that has more than one information.
- The enter layout defines the enter specification and the way the enter information could be break up and skim.
- The enter break up logically represents the knowledge to be processed through a person mapper.
- RecordReader communicates with the enter break up and converts the knowledge into key-value pairs appropriate to be learn through the mapper.
- The mapper works at the key-value pairs and offers an intermittent output, which matches for additional processing.
- Combiner is a mini reducer that plays mini aggregation at the key-value pairs generated through the mapper.
- Partitioner comes to a decision how outputs from combiners are despatched to the reducers.
- The output of the partitioner is shuffled and looked after. This output is fed as enter to the reducer.
- The reducer combines all of the intermediate values for the intermediate keys into an inventory referred to as tuples.
- The RecordWriter writes those output key-value pairs from reducer to the output information.
- The output information will get saved in HDFS.
The following phase of this MapReduce educational covers the structure of MapReduce.
MapReduce Structure
The structure of MapReduce is as proven:
There’s a shopper program or an API which intends to procedure the knowledge. It submits the task to the task tracker (useful resource supervisor on the subject of Hadoop YARN framework).
Hadoop v1 had a task tracker as grasp, main the Process Trackers. In Hadoop v2:
- Task tracker was once changed with ResourceManager
- Process tracker was once changed with NodeManager
The ResourceManager has to assign the task to the NodeManagers, which then handles the processing on each node. As soon as an utility to be run at the YARN processing framework is submitted, it’s treated through the ResourceManager.
The information which is saved in HDFS are damaged down into one or more than one splits relying at the enter layout. One or a lot of map duties, working inside the container at the nodes, paintings on those enter splits.
There may be some quantity of RAM applied for each and every map process. The similar information, which then is going throughout the decreasing segment, would additionally use some RAM and CPU cores. Internally, there are purposes which deal with deciding the collection of reducers, doing a mini scale back, studying and processing the knowledge from more than one information nodes.
That is how the MapReduce programming style makes parallel processing paintings. In any case, the output is generated and will get saved in HDFS.
Allow us to center of attention on a use case within the subsequent phase of this MapReduce educational.
MapReduce Use Case: World Warming
So, how are corporations, governments, and organizations the use of MapReduce?
First, we give an instance the place the objective is to calculate a unmarried price from a collection of knowledge thru aid.
Think we wish to know the extent wherein world warming has raised the sea’s temperature. Now we have enter temperature readings from 1000’s of buoys in every single place the globe. Now we have information on this layout:
(buoy, DateTime, longitude, latitude, low temperature, prime temperature)
We’d assault this downside in numerous map and scale back steps. The primary could be to run map over each buoy-dateTime studying and upload the typical temperature as a box:
(buoy, DateTime, longitude, latitude, low, prime, reasonable)
Then we’d drop the DateTime column and sum this stuff for all buoys to supply one reasonable temperature for each and every buoy:
(buoy n, reasonable)
Then the scale back operation runs. A mathematician would say this can be a pairwise operation on associative information. In different phrases, we take each and every of those (buoy, reasonable) adjoining pairs and sum them after which divide that sum through the rely to supply the typical of averages:
ocean reasonable temperature = reasonable (buoy n) + reasonable ( buoy n-1) + … + reasonable (buoy 2) + reasonable (buoy 1) / collection of buoys
Your Large Information Engineer Profession Awaits!
Put up Graduate Program In Information EngineeringDiscover Program
MapReduce Use Case: Drug Trials
Mathematicians and information scientists have historically labored in combination within the pharmaceutical trade. The discovery of MapReduce and the dissemination of knowledge science algorithms in large information techniques way odd IT departments can now take on issues that might have required the paintings of Ph.D. scientists and supercomputers previously.
Let’s take, for instance, an organization that conducts drug trials to turn whether or not its new drug works towards positive sicknesses, which is an issue that matches completely into the MapReduce style. On this case, we wish to run a regression model towards a collection of sufferers who’ve been given the brand new drug and calculate how efficient the drug is in preventing the illness.
Think the drug is used for most cancers sufferers. Now we have information issues like this:
{ (affected person identify: John, DateTime: 3/01/2016 14:00, dosage: 10 mg, dimension of most cancers tumor: 1 mm) }
Step one here’s to calculate the trade within the dimension of the tumor from one dateTime to subsequent. Other sufferers could be taking other quantities of the drug, so we’d wish to know what quantity of the drug works perfect. The usage of MapReduce, we’d attempt to scale back this downside to a couple linear courting like this:
% aid in tumor = x (amount of drug) + y (time period) + consistent price
If some correlation exists between the drug and the aid within the tumor, then the drug will also be stated to paintings. The style would additionally display to what stage it really works through calculating the mistake statistic.
Allow us to subsequent have a look at how MapReduce is beneficial in fixing issues at a big scale within the subsequent phase of this MapReduce educational.
Fixing Issues on a Massive Scale
What makes this a technological leap forward are two issues. First, we will be able to procedure unstructured information on a big scale, which means information that doesn’t simply are compatible right into a relational database. 2d, it takes the gear of knowledge science and allows them to run over disbursed datasets. Previously, the ones may simplest run on a unmarried pc.
The relative simplicity of the MapReduce gear and their energy and alertness to industry, army, science, and different issues explains why MapReduce is rising so unexpectedly. This enlargement will simplest build up as extra folks come to know the way to use those gear to their scenario.
If you wish to be informed extra about Large Information and Information Engineering, then take a look at Simplilearn’s Skilled Certificates Program In Information Engineering, designed in partnership with Purdue College and IBM. This system is best for serving to you get began within the huge international of Large Information.
supply: www.simplilearn.com










